蚂蚁金服 - Elasticsearch深度分页问题及不同需求下的解决方案
蚂蚁金服 - Elasticsearch深度分页问题及不同需求下的解决方案
1. 什么是深度分页(Deep paging)
1.1. ES中from+size分页
分页问题是Elasticsearch中最常见的查询场景之一,正常情况下分页代码如实下面这样的:
GET order_2290w/_search
{
"from": 0,
"size": 5
}
输出结果如下图:
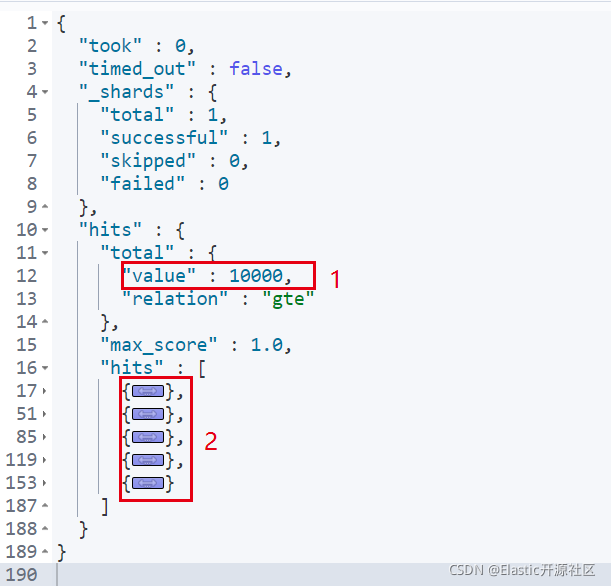
很好理解,即查询第一页的5条数据。图中数字2即返回的五条文档数据。但是如果我们查询的数据页数特别大,达到什么程度呢?当from + size大于10000的时候,就会出现问题,如下图报错信息所示:
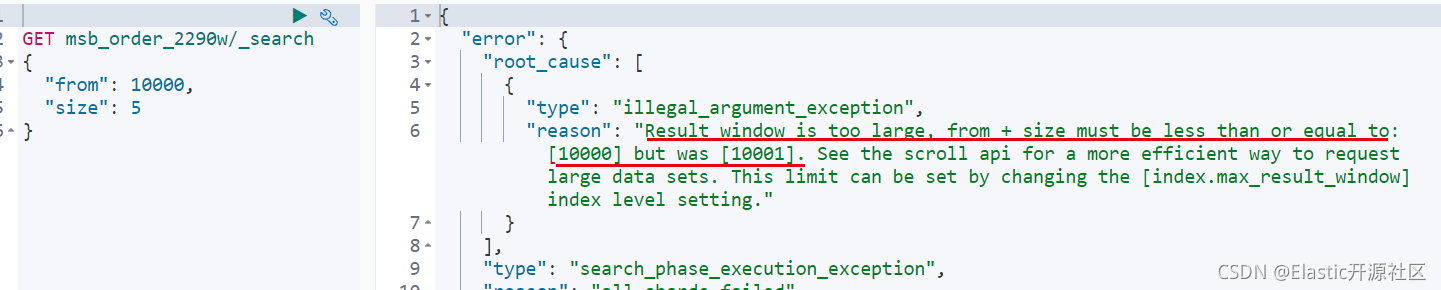
报错信息的解释为当前查询的结果超过了10000的最大值。那么疑问就来了,明明只查询了5条数据,为什么它计算最大值要加上我from的数量呢?而且Elasticsearch不是号称PB及数据秒级查询,几十亿的数据都没问题,怎么还限制最大查询前10000条数据呢?这里有一个字很关键:“前”,前10000条意味着什么?意味着数据肯定是按照某种顺序排列的,ES中如果不人工指定排序字段,那么最终结果将按照相关度评分排序。
分布式系统都面临着同一个问题,数据的排序不可能在同一个节点完成。一个简单的需求,比如:
1.2. 案例解释什么是深分页
从10万名高考生中查询成绩为的10001-10100位的100名考生的信息。
看似简单的查询其实并不简单,我们来画图解释一下:
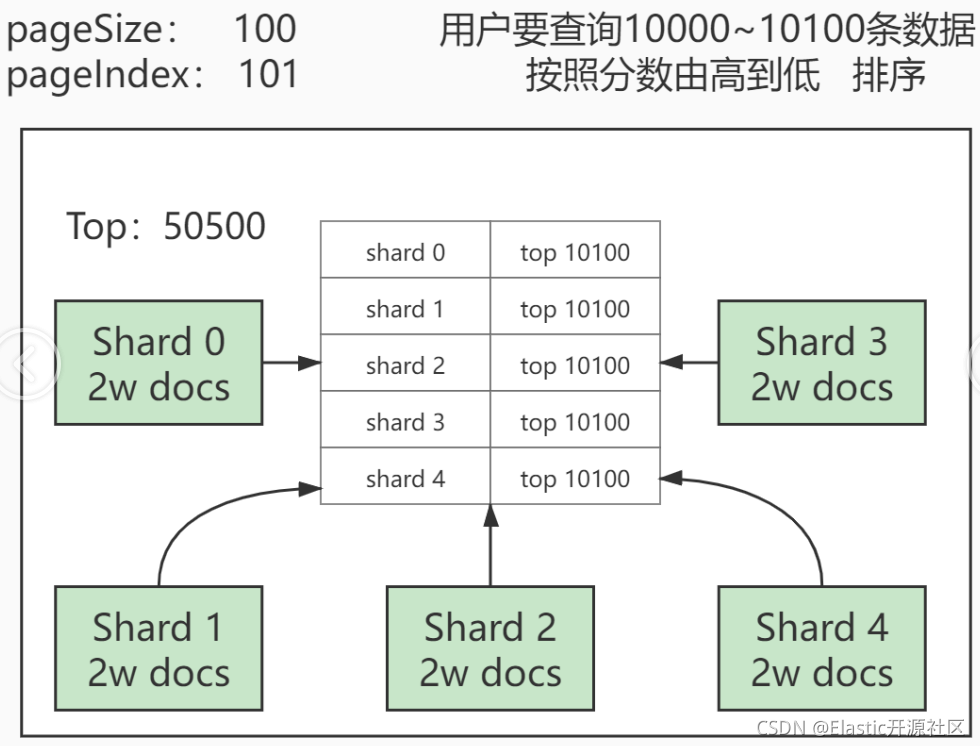
假设10万名考生的考试信息被存放在一个exam_info索引中,由于索引数据在写入是并无法判断在执行业务查询时的具体排序规则,因此排序是随机的。而由于ES的分片和数据分配策略为了提高数据在检索时的准确度,会把数据尽可能均匀的分布在不同的分片。假设此时我们有五个分片,每个分片中承载2万条有效数据。按照需求我们需要去除成绩在10001到10100的一百名考生的信息,就要先按照成绩进行倒序排列。然后按照page_size: 100&page_index: 101进行查询。即查询按照成绩排序,第101页的100位学员信息。
单机数据库的查询逻辑很简单,先按照把10万学生成绩排序,然后从前10100条数据数据中取出第10001-10100条。即按照100为一页的第101页数据。
但是分布式数据库不同于单机数据库,学员成绩是被分散保存在每个分片中的,你无法保证要查询的这一百位学员的成绩一定都在某一个分片中,结果很有可能是存在于每个分片。换句话说,你从任意一个分片中取出的前10100位学员的成绩,都不一定是总成绩的前10100。更不幸的是,唯一的解决办法是从每个分片中取出当前分片的前10100名学员成绩,然后汇总成50500条数据再次排序,然后从排序后的这50500个成绩中查询前10100的成绩,此时才能保证一定是整个索引中的成绩的前10100名。
如果还不理解,我再举个例子用来类比:从保存了世界所有国家短跑运动员成绩的索引中查询短跑世界前三,每个国家类比为一个分片的数据,每个国家都会从国家内选出成绩最好的前三位参加最后的竞争,从每个国家选出的前三名放在一起再次选出前三名,此时才能保证是世界的前三名。
2. 深度分页会带来什么问题
从上面案例中不难看出,每次有序的查询都会在每个分片中执行单独的查询,然后进行数据的二次排序,而这个二次排序的过程是发生在heap中的,也就是说当你单次查询的数量越大,那么堆内存中汇总的数据也就越多,对内存的压力也就越大。这里的单次查询的数据量取决于你查询的是第几条数据而不是查询了几条数据,比如你希望查询的是第10001-10100这一百条数据,但是ES必须将前10100全部取出进行二次查询。因此,如果查询的数据排序越靠后,就越容易导致OOM(Out Of Memory)情况的发生,频繁的深分页查询会导致频繁的FGC。
ES为了避免用户在不了解其内部原理的情况下而做出错误的操作,设置了一个阈值,即max_result_window,其默认值为10000,其作用是为了保护堆内存不被错误操作导致溢出。因此也就出现了文章一开始所演示的问题。
3. max_result_window参数
max_result_window是分页返回的最大数值,默认值为10000。max_result_window本身是对JVM的一种保护机制,通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致OOM。
在很多业务场景中经常需要查询10000条以后的数据,当遇到不能查询10000条以后的数据的问题之后,网上的很多答案会告诉你可以通过放开这个参数的限制,将其配置为100万,甚至1000万就行。但是如果仅仅放开这个参数就行,那么这个参数限制的意义有何在呢?如果你不知道这个参数的意义,很可能导致的后果就是频繁的发生OOM而且很难找到原因,设置一个合理的大小是需要通过你的各项指标参数来衡量确定的,比如你用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大约好。
4. 深度分页问题的常见解决方案
4.1. 尝试避免深度分页
目前人类对抗疾病最有效的手段:打疫苗。没错,能方式发生的问题总比发生之后再治理来的强。同样,解决深度分页问题最好的办法也是预防,也就是能避免最好是避免使用深度分页。我相信不服气的小伙儿伴已经满嘴质疑了,我们怎么能要求用户去做什么、不做什么呢?用户想深度分页检索你凭什么不让呢?技术要服务于业务!不能用妥协用户体验来解决技术问题…
带着这些质疑,我们先来看一看众多大型搜索引擎面对深度分页问题是如何处理的:
首先是以百度和谷歌为代表的全文搜索引擎:
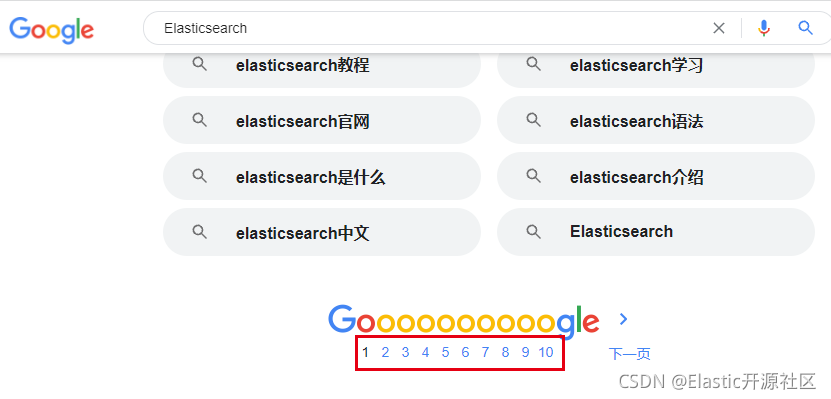
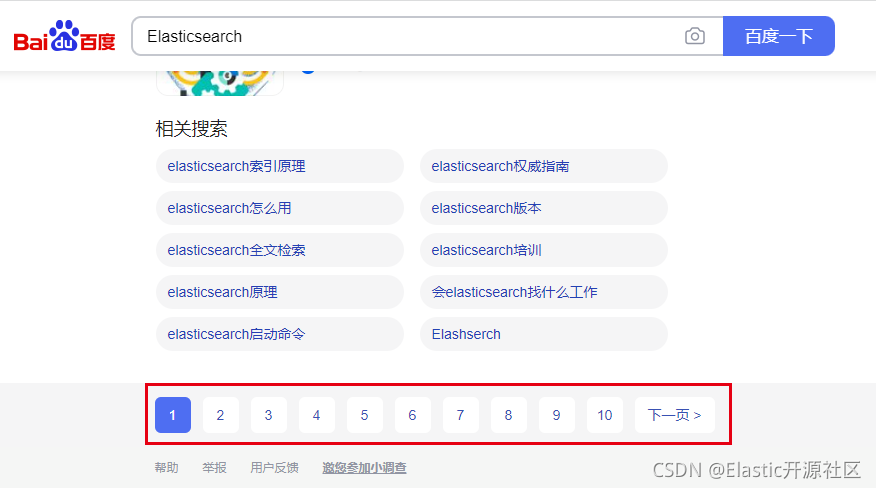
谷歌、百度目前作为全球和国内做大的搜索引擎(不加之一应该没人反对吧。O(∩_∩)O~)。不约而同的在分页条中删除了“跳页”功能,其目的就是为了避免用户使用深度分页检索。
这里也许又双叒叕会有人不禁发问:难道删除“跳页”就能阻止用户查询很多页以后的数据了吗?我直接狂点下一页不也是深度分页?好我暂时先不反驳这里的提问,但是我也发出一个反问,至少删除跳页,可以阻挡哪些刻意去尝试深度分页的“恶意用户”,真正想通过搜索引擎来完成自己检索需求的用户,通常来说都会首先查看第一页数据,因为搜索引擎是按照“相关度评分”进行排名的,也就是说,第一页的数据很往往是最符合用户预期结果的(暂时不考虑广告、置顶等商业排序情况)。
下面我们再看一下以中国最大电商平台“淘宝”为代表的垂直搜索引擎是怎么解决的:
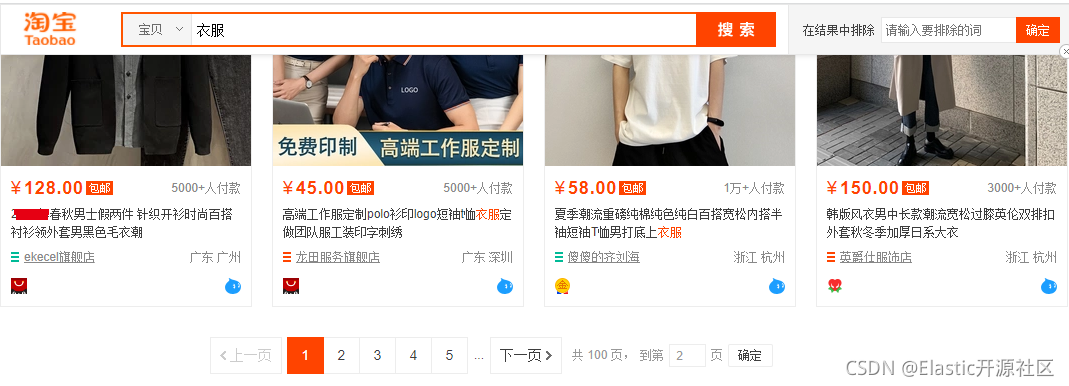
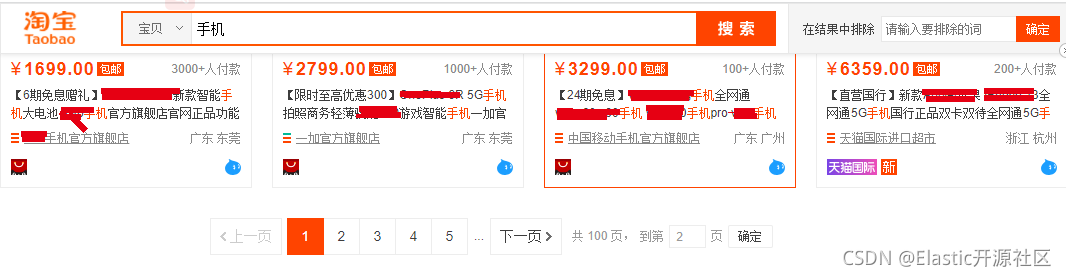
我们分别尝试搜索较大较为宽泛的商品种类,以使其召回结果足够多(这里以手机和衣服为例,已屏蔽掉了商品品牌和型号,以避免广告嫌疑(#.#))。
虽然这里没有删除“跳页”功能,但这里可以看到一个有趣的现象,不管我们搜索什么内容,只要商品结果足够多,返回的商品列表都是仅展示前100页的数据,我们不难发现,其实召回的商品被“截断”了,不管你有多少,我都只允许你查询前100页,其实这本质和ES中的max_result_window作用是一样的,都是限制你去搜索更深页数的数据。
手机端APP就更不用说了,直接是下拉加载更多,连分页条都没有,相当于你只能点击“下一页”。
那么回到当初的问题,我们牺牲了用户体验了吗?
不仅没有,而且用户体验大大提升了!
- 首先那些直接输入很大的页码,直接点击跳页的用户,本身就是恶意用户,阻止其行为是理所应当,因此删除“跳页”,功能并无不妥!
- 其次,真正的通过搜索引擎来检索其意向数据的用户,只关心前几页数据,即便他通过分页条跳了几页,但这种搜索并不涉及深度分页,即便它不停的点下去,我们也有其它方案解决此问题。
- 类似淘宝这种直接截断前100页数据的做法,看似暴力,其实是在不牺牲用户体验的前提下,极大的提升了搜索的性能,这也变相的为哪些“正常用户”,提升了搜索体验,何乐不为?
4.2. 滚动查询:Scroll Search
官方已不推荐使用滚动查询进行深度分页查询,因为无法保存索引状态。
适合场景
单个滚动搜索请求中检索大量结果,即非“C端业务”场景
使用
GET <index>/_search?scroll=1m
{
"size": 100
}
d | Days |
|---|---|
h | Hours |
m | Minutes |
s | Seconds |
ms | Milliseconds |
micros | Microseconds |
nanos | Nanoseconds |
为了使用滚动,初始搜索请求应该scroll在查询字符串中指定参数,该参数告诉Elasticsearch应该保持“搜索上下文”多长时间,例如?scroll=1m。结果如下:
{
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAABVWsWN3Q4dDJjcVVRQ0NBbllGMmFqN0ZVZw==",
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 21921750,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
...
]
}
}
上述请求的结果包含一个_scroll_id,应将其传递给scrollAPI 以检索下一批结果。
滚动返回在初始搜索请求时与搜索匹配的所有文档。它会忽略对这些文档的任何后续更改。该scroll_id标识一个搜索上下文它记录身边的一切Elasticsearch需要返回正确的文件。搜索上下文由初始请求创建,并由后续请求保持活动状态。
注意
- Scroll上下文的存活时间是滚动的,下次执行查询会刷新,也就是说,不需要足够长来处理所有数据,它只需要足够长来处理前一批结果。保持旧段处于活动状态意味着需要更多的磁盘空间和文件句柄。确保您已将节点配置为具有充足的空闲文件句柄。
- 为防止因打开过多Scrolls而导致的问题,不允许用户打开超过一定限制的Scrolls。默认情况下,打开Scrolls的最大数量为 500。此限制可以通过search.max_open_scroll_context集群设置进行更新 。
清除滚动上下文
scroll超过超时后,搜索上下文会自动删除。然而,保持Scrolls打开是有代价的,因此一旦不再使用该clear-scrollAPI ,就应明确清除Scroll上下文。
#清除单个
DELETE /_search/scroll
{
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
#清除多个
DELETE /_search/scroll
{
"scroll_id" : [
"scroll_id1",
"scroll_id2"
]
}
#清除所有
DELETE /_search/scroll/_all
4.3. Search After
代码
GET product/_search
{
"size": 2,
"query": {
"match_all": {}
},
"sort": [
{
"price": "desc",
"_id": "asc"
}
]
}
GET product/_search
{
"size": 2,
"query": {
"match_all": {}
},
"search_after": [
5999,
"6"
],
"sort": [
{
"price": "desc",
"_id": "asc"
}
]
}
如何使用search after解决大型搜索引擎场景下深度分页问题
- 不支持向前搜索,只能向后执行;
- 每次只能向后搜索1页数据;
- 适用于C端业务。
以百度为例,默认加载10页数据,假设每页数据为10条,其实对于ES而言,还不涉及深度分页问题,因为只是查询了一百条数据。
如果项目并发请求并不高,可以单次查询100条数据。或者采用懒加载的方式异步请求前十页数据。后面的数据采用search after向后翻页即可。
引用资料
- https://blog.csdn.net/wlei0618/article/details/120800632
