Redis集群中数据倾斜问题的产生和解决方案
Redis集群中数据倾斜问题的产生和解决方案
1. 前言
在服务端系统服务开发中,缓存是一种常用的技术,它可以提高系统对请求的处理效率,而redis又是缓存技术栈中的一个佼佼者,广泛的应用于各种服务系统中。在大型互联网服务中,每天需要处理的请求和存储的缓存数据都是海量的,在这些大型系统中,使用单实例的redis,很难满足系统超高的并发请求以及海量数据缓存需求。大型的互联网服务中对于redis的使用,往往采用集群架构,通过横向扩展redis实例规模的方式,以较低的成本,来提升缓存系统对数据请求的处理效率和数据存储容量。
redis集群架构虽然有众多优点,但是事物往往都是有双面性的,在解决某些场景下的问题后,又会在另外的场景下有带来问题。当然redis集群模式,也是符合这个规律的。redis集群模式下,会增加运维的复杂度,限制了redis中某些命令的使用(范围查询,事务操作的使用等),除了这些常见的问题外,数据倾斜问题,是redis集群模式下一个比较隐蔽的问题,只有在一些特殊的场景下才会出现,但是该问题带来的影响确实巨大的。
在redis集群模式下,数据会按照一定的分布规则分散到不同的实例上。如果由于业务数据特殊性,按照指定的分布规则,可能导致不同的实例上数据分布不均匀,如以下场景:有些切片实例上数据分布量较大,有些实例上数据分布量较少;有些实例上保存了热点数据,数据访问量较大,有些实例上保存数据相对较"冷",几乎没有访问量。那么存储数据量大的实例,或者保存热点数据的实例,资源利用率会比较高,负载压力较大,导致其对数据请求响应变慢。 此时就产生了数据倾斜。
2. 数据倾斜种类
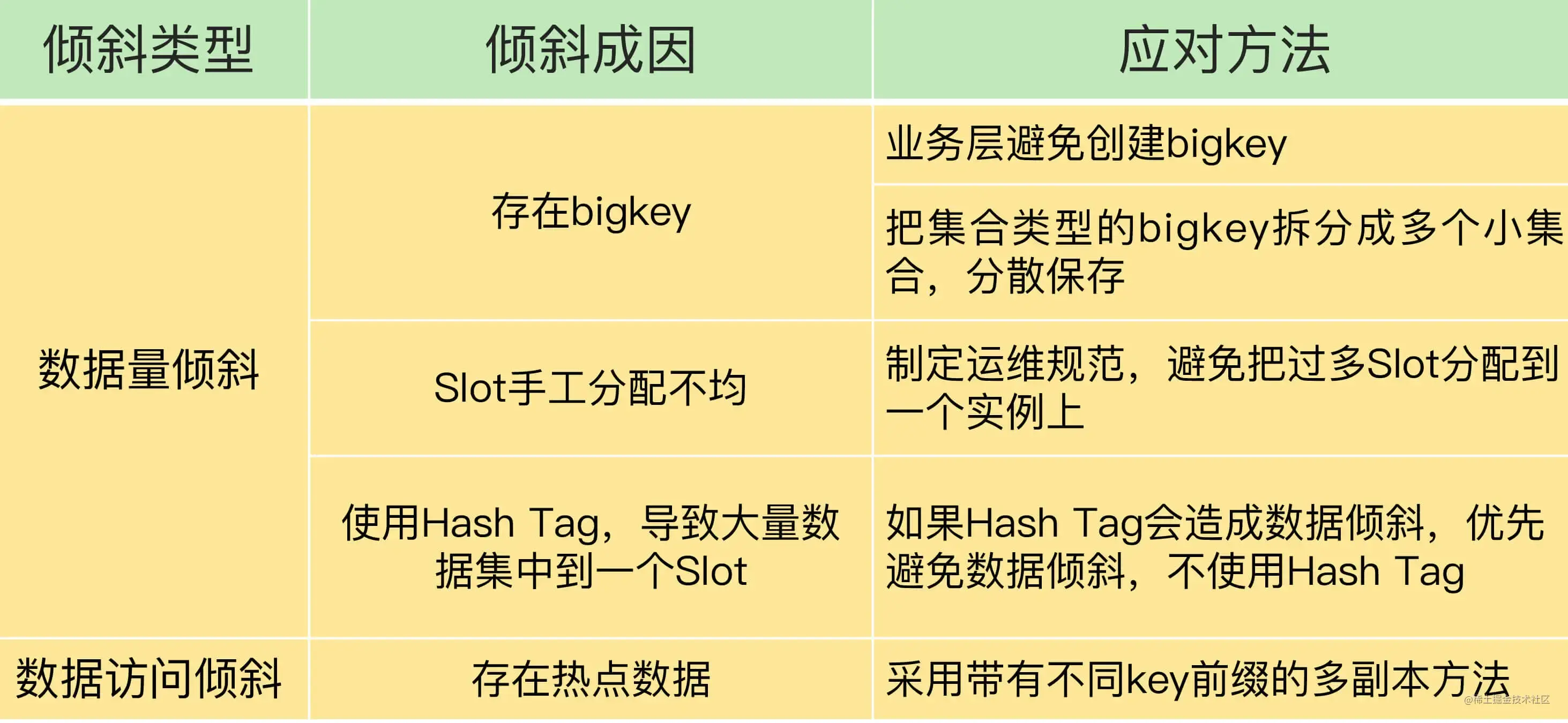
数据倾斜有两类:
- 数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多。
- 数据访问倾斜:虽然每个集群实例上的数据量相差不大,但是某个实例上的数据是热点数据,被访问得非常频繁。
3. 数据量倾斜分析
当数据量倾斜发生时,数据在切片集群的多个实例上分布不均衡,大量数据集中到了一个或几个实例上。
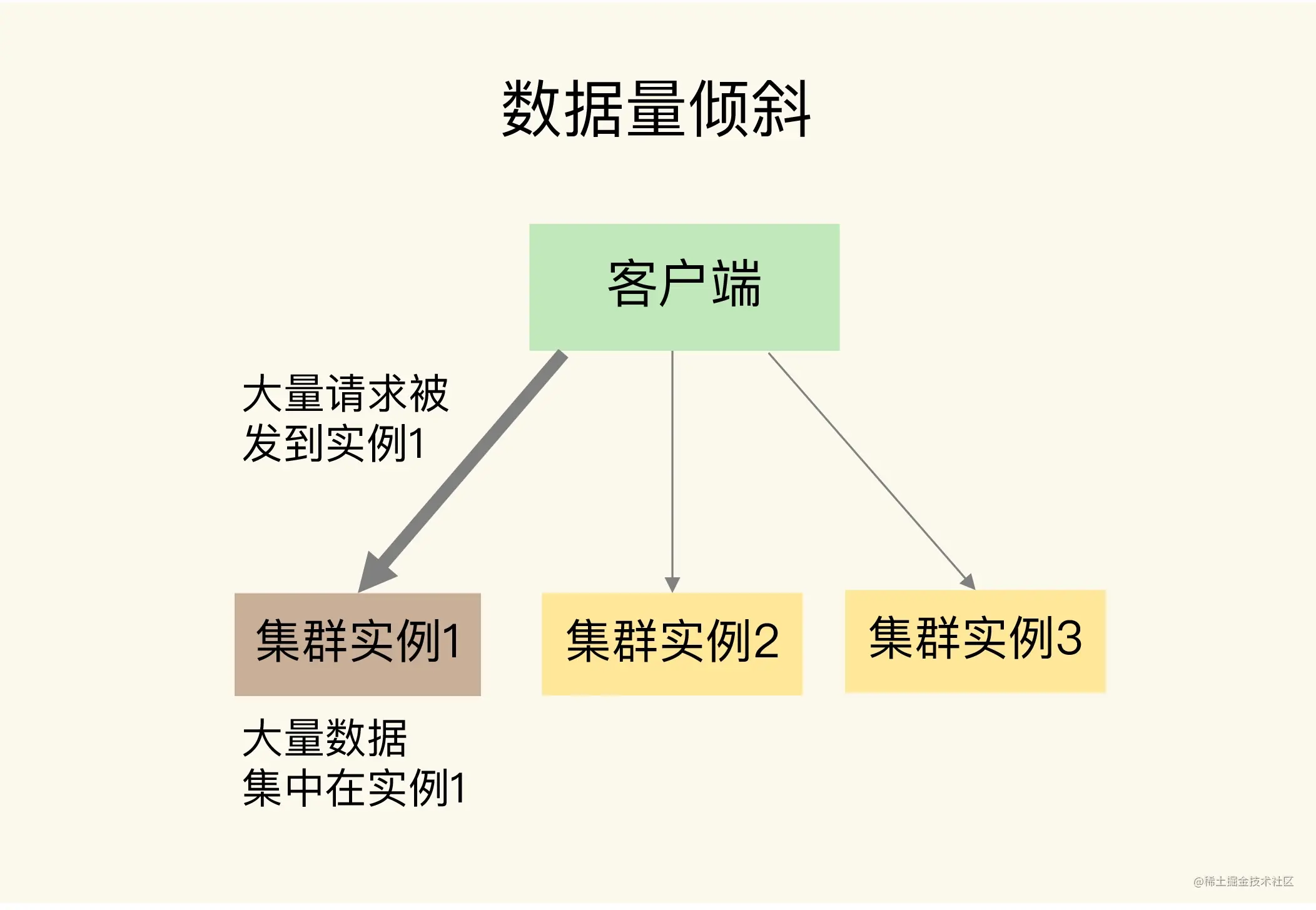
那么,数据量倾斜是怎么产生的呢?这主要有三个原因,分别是某个实例上保存了bigkey、Slot 分配不均衡以及Hash Tag。
3.1. 存在bigkey
某个实例上正好保存了 bigkey。bigkey的value值很大(String 类型),或者是bigkey保存了大量集合元素(集合类型),会导致这个实例的数据量增加,内存资源消耗也相应增加。
一个根本的应对方法是,我们在业务层生成数据时,要尽量避免把过多的数据保存在同一个键值对中。
此外,如果bigkey正好是集合类型,我们还有一个方法,就是把bigkey拆分成很多个小的集合类型数据,分散保存在不同的实例上。
3.2. Slot分配不均衡
如果集群运维人员没有均衡地分配 Slot,就会有大量的数据被分配到同一个Slot中,而同一个Slot只会在一个实例上分布,这就会导致,大量数据被集中到一个实例上,造成数据倾斜。
为了应对这个问题,我们可以通过运维规范,在分配之前,我们就要避免把过多的Slot分配到同一个实例。
不同集群上查看Slot分配情况的方式不同:如果是Redis Cluster,就用CLUSTER SLOTS命令;如果是Codis,就可以在codis dashboard上查看。
Slot迁移
如果是已经分配好Slot的集群,我们可以先查看Slot和实例的具体分配关系,从而判断是否有过多的Slot集中到了同一个实例。如果有的话,就将部分Slot迁移到其它实例,从而避免数据倾斜。
在 Redis Cluster 中,我们可以使用 3 个命令完成Slot迁移。
- CLUSTER SETSLOT:使用不同的选项进行三种设置,分别是设置Slot要迁入的目标实例,Slot 要迁出的源实例,以及Slot所属的实例。
- CLUSTER GETKEYSINSLOT:获取某个Slot中一定数量的 key。
- MIGRATE:把一个 key 从源实例实际迁移到目标实例。
3.3. Hash Tag使用不当
Hash Tag是指加在键值对 key 中的一对花括号{}。这对括号会把 key 的一部分括起来,客户端在计算 key 的 CRC16 值时,只对Hash Tag花括号中的 key 内容进行计算。如果没用Hash Tag的话,客户端计算整个key的CRC16的值。
使用Hash Tag的好处是,如果不同key的Hash Tag内容都是一样的,那么,这些key对应的数据会被映射到同一个Slot中,同时会被分配到同一个实例上。
那么,Hash Tag一般用在什么场景呢?其实,它主要是用在Redis Cluster和Codis中,支持事务操作和范围查询。因为Redis Cluster和Codis本身并不支持跨实例的事务操作和范围查询,当业务应用有这些需求时,就只能先把这些数据读取到业务层进行事务处理,或者是逐个查询每个实例,得到范围查询的结果。
但是,使用Hash Tag的潜在问题,就是大量的数据可能被集中到一个实例上,导致数据倾斜,集群中的负载不均衡。 那么,该怎么应对这种问题呢?我们就需要在范围查询、事务执行的需求和数据倾斜带来的访问压力之间,进行取舍了。
我的建议是,如果使用Hash Tag进行切片的数据会带来较大的访问压力,就优先考虑避免数据倾斜,最好不要使用Hash Tag进行数据切片。因为事务和范围查询都还可以放在客户端来执行,而数据倾斜会导致实例不稳定,造成服务不可用。
4. 数据访问倾斜分析
一旦热点数据被存在了某个实例中,那么,这个实例的请求访问量就会远高于其它实例,面临巨大的访问压力。
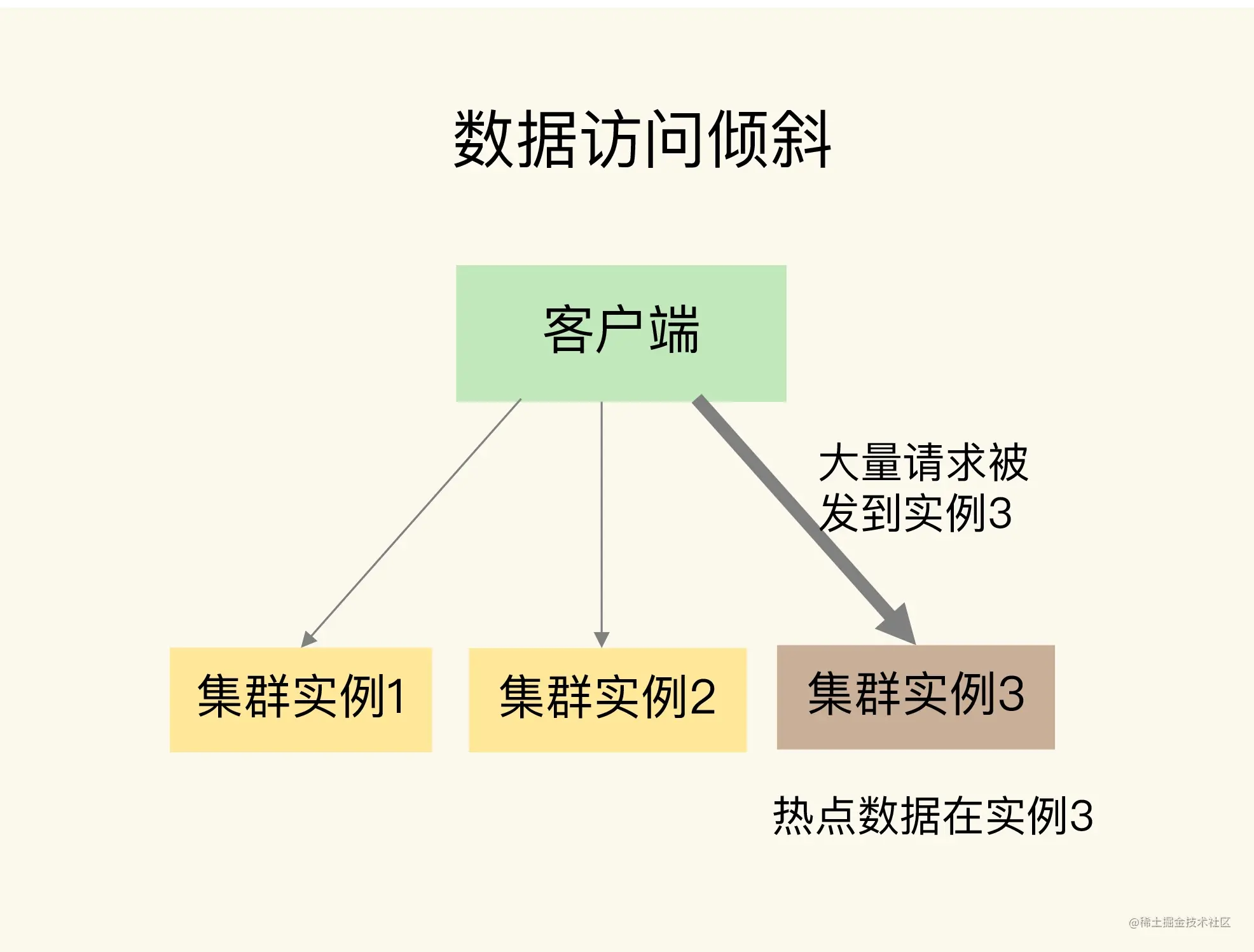
通常来说,热点数据以服务读操作为主,在这种情况下,我们可以采用热点数据多副本的方法来应对。
这个方法的具体做法是,我们把热点数据复制多份,在每一个数据副本的 key 中增加一个随机前缀,让它和其它副本数据不会被映射到同一个Slot中。这样一来,热点数据既有多个副本可以同时服务请求,同时,这些副本数据的 key 又不一样,会被映射到不同的Slot中。
在给这些Slot分配实例时,我们也要注意把它们分配到不同的实例上,那么,热点数据的访问压力就被分散到不同的实例上了。
热点数据多副本方法只能针对只读的热点数据。如果热点数据是有读有写的话,就不适合采用多副本方法了,因为要保证多副本间的数据一致性,会带来额外的开销。
对于有读有写的热点数据,我们就要给实例本身增加资源了,例如使用配置更高的机器,来应对大量的访问压力。
5. 总结
在构建切片集群时,尽量使用大小配置相同的实例(例如实例内存配置保持相同),这样可以避免因实例资源不均衡而在不同实例上分配不同数量的Slot。
引用资料
- https://blog.csdn.net/Java_LingFeng/article/details/128788849
