SQL - MySQL 数据库日志 binlog、redo log、undo log 扫盲
SQL - MySQL 数据库日志 binlog、redo log、undo log 扫盲
日志是数据库中比较重要的组成部分,很多核心的功能必须依靠日志才能完成。该篇文章简要介绍了
binlog、redo log与undo log,能够在一定程度上拓宽对mysql日志的整体认识。
1. binlog
又称归档日志,。
binlog是一种只记录对表中数据以及对表结构产生更改操作的二进制文件,比如有insert、update、delete、create table、alter table等操作,不记录select、show,因为这些操作不会产生任何更改。不过就算一个update未产生数据变化,也是会被记录进去的。
你可以理解binlog是直接记录sql语句,或者说记录原始sql逻辑,因此binlog属于逻辑日志。
binlog是追加写入的,一个文件写满,会重新创建一个文件继续写,文件名称是mysql-bin.xxxxxx,例如myql-bin.000001,序号部分会递增。
1.1. binlog格式
binlog有三种格式,可以通过binlog-format来设定。
1.1.1. STATEMENT
直接记录操作的sql语句,例如update student set name='tom' where id=1;
优点: 这种格式的binlog,可以直接进行阅读。不记录具体的行数据,日志量不会很大,性能较优。
缺点: 当binlog用于主从之间的复制时,如果当前的sql语句为随机函数rand()、当前日期now()等,在重现之后具有不同的值,具有歧义性,可能会造成复制后数据不一致。
1.1.2. ROW
对于update student set name='tom' where id=1操作,会记录id=1这条数据中name字段在修改前与修改后的数据。
优点: 准确性强
缺点: 可读性差,需要借助mysqlbinlog解析。
如果经常修改一些字段比较长的数据,会造成生成的binlog日志量变多,性能稍弱。
当然,alter table等直接改变表结构的语句,也会快速增加日志量与磁盘IO。
1.1.3. MIXED
其实就是一种对STATEMENT与ROW的混合使用方式
对不会造成歧义的操作使用STATEMENT格式进行记录,否则使用ROW格式记录。
对表结构的修改操作,也使用ROW格式进行记录。
不过,比较推荐的是ROW格式,特别是在SSD、云端存储、大带宽普及的今天,这点儿的存储空间与磁盘IO还是吃得消的,滴滴基于Binlog的采集架构就是直接使用的ROW格式。
1.2. binlog使用场景
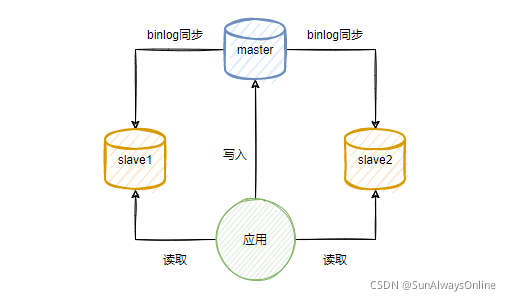
1.2.1. 主从复制
当我们使用主从结构的mysql时,从库需要同步主库的数据。
这个时候主库会将自己的binlog异步发送给从库,从库在本地完成sql回放,来达到主从数据一致的目的。
主从复制之间可能会存在延迟,当主库只负责写,从库只负责读时,写完主库之后的立马读从库,可能会出现问题。
1.2.2. 数据恢复
当误删生产数据时,可以通过binlog来恢复。
找到生产库最近的一次全量备份,首先由全量备份恢复到临时库中。
接着从全量备份的时间点开始,重放binlog一直到mysql不产生新的binlog为止,另外要注意删除binlog中误操作的语句,最后切换临时库为生产库。
值得注意的一点是,。
2. redo log
又称重做日志,是Innodb引擎中特有的日志。如果当前使用的引擎是Myisam或者Memory,那就无从谈起redo log。和binlog的内容不同,redo log记录了“在某个数据页上做了哪些修改”,属于物理日志。
2.1. 为什么要有redo log?
Innodb引擎是以页为单位来和磁盘交互的,一般来说,如果一个事务提交后,需要将修改后的数据页写回到磁盘中。
如果本次事务只修改当前数据页中的几个Byte,直接将当前数据页的所有内容刷到磁盘后,涉及到大量的随机写,IO成本很高,性能比较低。
如果事务提交后,先将“对哪个数据页做了哪些修改”顺序写入redo log,之后会在合适的时机写回到buffer pool(你可以把buffer pool理解为缓冲池,如果查询到一条记录时,会将记录所在的数据页加载进缓冲池中。之后再进行查找时,先查询缓冲池,查不到再查磁盘,查到了就再放入到缓冲池中。这样做,在一定程度上可以减少IO成本,提升性能)中,最后将buffer pool中的数据页刷盘,在一定程度上可以减少IO成本。
此外,。当redo log与binlog结合在一起的时候,光芒就出现了,此处应该有迪迦。redo log中较实际数据页中多出来的那部分日志,就是崩溃后用于恢复的日志。
2.2. redo log记录方式
和binlog追加写不同,redo log采用的是循环写。之所以用循环写,是因为之前恢复的数据再保存在redo log中就没有任何意义了。
假设redo log最终会写入到4个文件中,每个文件的大小都是1GB,则此时能够记录的最大日志量为4GB。
比如先从1号文件中写入,写满之后,就换到2号文件中。4个文件全部写满后,再回到1号文件从头继续写。
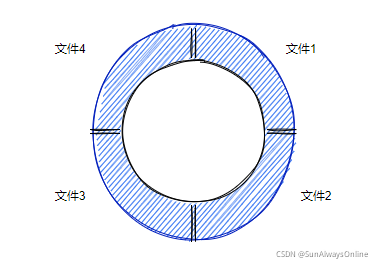
这里还有两个指针,write position与check point
2.2.1. write position
指向redo log的记录进度,write position指针走过的区域,代表着redo log的日志量逐渐增长。
2.2.2. check point
指向数据页刷盘后的恢复进度,check point指针走过的区域,会将区域内redo log数据用于恢复,接着将redo log擦除。
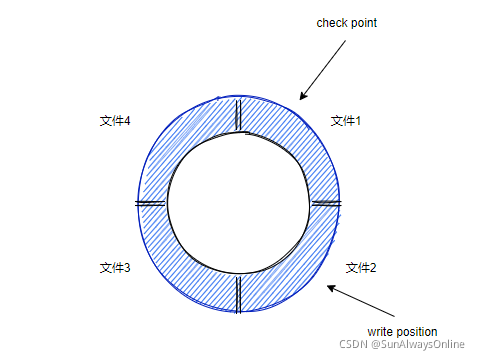
两个指针的运动方向,都是顺时针方向。
因此,从write position顺时针到check point之间的区域,都是空着的部分。
当redo log记录过快时,write position可能会追赶上check point。此时就需要停止redo log记录,并将所有文件中的redo log恢复。
在这里,有必要总结一下binlog与redo log的区别。
2.3. binlog与redo log区别
| binlog | redo log | |
|---|---|---|
| 日志归属 | 由Server层实现,所有的引擎都可以使用 | Innodb引擎中特有的日志 |
| 日志类型 | 逻辑日志,记录原始的sql逻辑或数据变更的前后内容 | 物理日志,记录在哪个数据页上进行了哪些更改 |
| 写入方式 | 追加写,写满则创建一个新文件继续写 | 循环写,全部写满就从头开始 |
| 适用场景 | 主从同步与误删恢复 | 崩溃恢复 |
在一条类型为update的sql语句的执行背后,涉及到binglog与redo log的两阶段提交,这个也会另开篇幅。
3. Undo log
。
mysql在执行sql语句时,会将一条逻辑相反的日志保存到undo log中。因此,undo log中记录的也是逻辑日志。
- 当sql语句为insert时,会在undo log中记录本次插入的主键id。等事务回滚时,delete此id即可。
- 当sql语句为update时,会在undo log中记录修改前的数据。等事务回滚时,再执行一次update,得到原来的数据。
- 当sql语句为delete时,会在undo log中记录删除前的数据。等事务回滚时,insert原来的数据即可。
数据库事务四大特性中的原子性,即事务具有不可分割性,要么全部成功,要么全部失败,其底层就靠undo log实现。在某一步执行失败时,会对之前事务的语句进行回滚。
另外,undo log与ReadView合作可以实现。
3.1. MVCC
对于MVCC,简单来讲,就是mysql保存了一行数据在多个时间点的快照,是一种使用空间换取时间的策略,能做到读(快照读,可以理解就是普通的select语句)写不加锁。
你可以暂时理解为,每一份快照包含了一行undo log日志,各个版本的快照通过指针连接起来,这样可以顺着指针快速找到上一份快照。
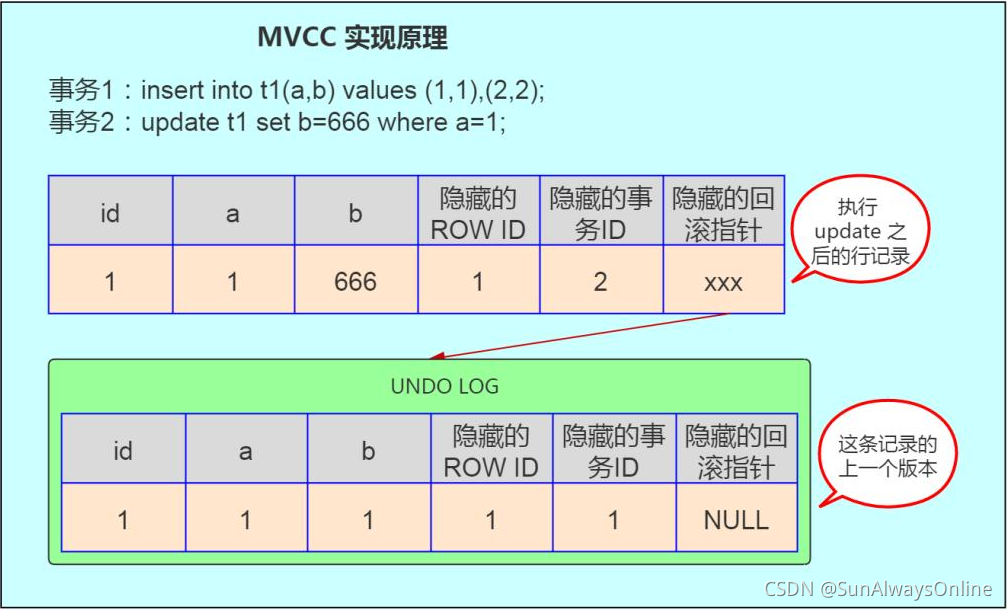
关于MVCC实现原理:SQL - MySQL多版本并发控制机制(MVCC)实现原理与源码分析
引用资料
- https://blog.csdn.net/qq_33591903/article/details/120517405
